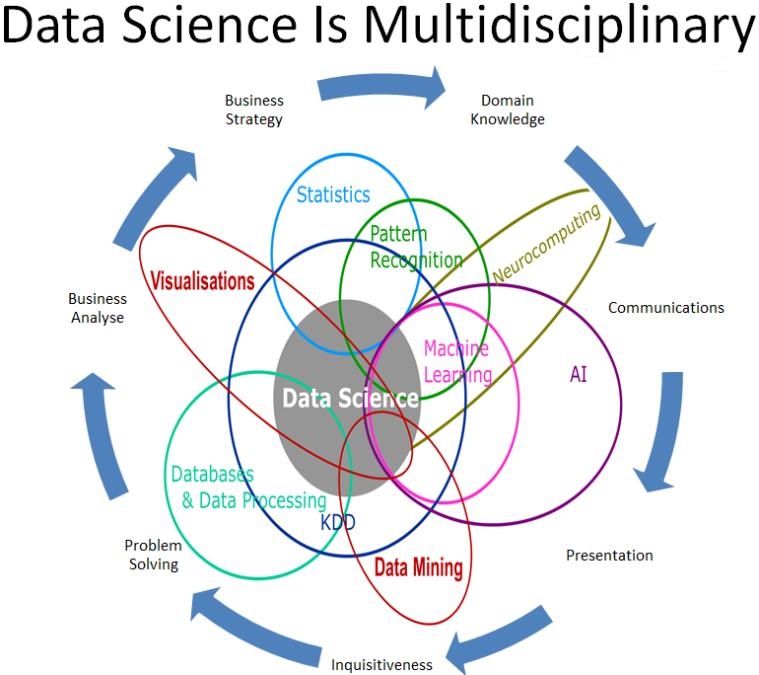
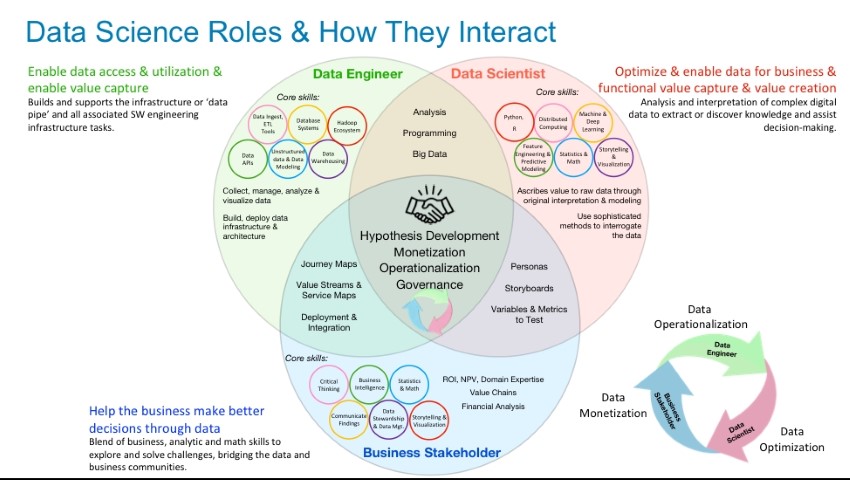
In no particular order, let's get to know the Top Skills in the field of Data Science. Together these skills will put you foremost in the job market, ahead of everybody. These skills will make sure that you are ready for the new technology trends and more significant challenges in the field of Data Science.
Programming Skills
No matter what type of company or role you're interviewing for, you're likely going to be expected to know how to use the tools of the trade. This means a statistical programming language, like R or Python, and a database querying language like SQL. Even though NoSQL and Hadoop have become a large component of data science, it is still expected that a candidate will be able to write and execute complex queries in SQL. One need to be proficient in SQL and advanced Database concepts. Very often the Data Science programs runs for many hours, if not days. Often, the data to be processed is in Terabytes or Petabytes.
Statistics
Good understanding of statistics is vital as in all fields of Data Science. You should be familiar with statistical tests, distributions, maximum likelihood estimators, etc. This will also be the case for machine learning, but one of the more important aspects of your statistics knowledge will be understanding when different techniques are (or aren't) a valid approach. Statistics is important at all company types, but especially data-driven companies where stakeholders will depend on your help to make decisions and design / evaluate experiments. Probability with the help of statistical methods helps make estimates for further analysis. Statistics is mostly dependent on the theory of probability.
Machine Learning
If you're at a large company with huge amounts of data, or working at a company where the product itself is especially data-driven (e.g. Netflix, Google Maps, Uber), it may be the case that you'll want to be familiar with machine learning methods. This can mean things like k-nearest neighbors, random forests, ensemble methods, and more. It's true that a lot of these techniques can be implemented using R or Python libraries-because of this, it's not necessary to become an expert on how the algorithms work. More important is to understand the broad strokes and really understand when it is appropriate to use different techniques.
Multivariable Calculus & Linear Algebra
Understanding these concepts is most important at companies where the product is defined by the data, and small improvements in predictive performance or algorithm optimization can lead to huge wins for the company. In an interview for a data science role, you may be asked to derive some of the machine learning or statistics results you employ elsewhere. Or, your interviewer may ask you some basic multivariable calculus or linear algebra questions, since they form the basis of a lot of these techniques. You may wonder why a data scientist would need to understand this when there are so many out of the box implementations in Python or R. The answer is that at a certain point, it can become worth it for a data science team to build out their own implementations in house.
Big Data
Although this isn't always a requirement, it is heavily preferred in many cases. Having experience with Hive or Pig is also a strong selling point. Familiarity with cloud tools such as Amazon S3 can also be beneficial. A study carried out by CrowdFlower on 3490 LinkedIn data science jobs ranked Apache Hadoop as the second most important skill for a data scientist with 49% rating.
As a data scientist, you may encounter a situation where the volume of data you have exceeds the memory of your system or you need to send data to different servers, this is where Hadoop comes in. You can use Hadoop to quickly convey data to various points on a system. That's not all. You can use Hadoop for data exploration, data filtration, data sampling and summarization.