Background
AI has penetrated every industry, leading to bold claims like 'data is the new oil' and 'AI is the new electricity'.
Three business titans - Jeff Bezos, Bill Gates, and Elon Musk - recently became centibillionaires, as their AI-powered products and services have taken off.
AI has traditionally been limited largely to academia and big tech, for three main reasons:
1. AI used to be expensive, requiring teams of data scientists, who average six-figure salaries in the United States.
2. AI used to be time-consuming, with even simple Proofs-of-Concept taking at least 1-2 months.
3. AI used to be exceptionally challenging, with intensive data engineering and deployment demands.
AutoML solves these three problems, by enabling organizations to quickly, easily, and affordably implement AI.
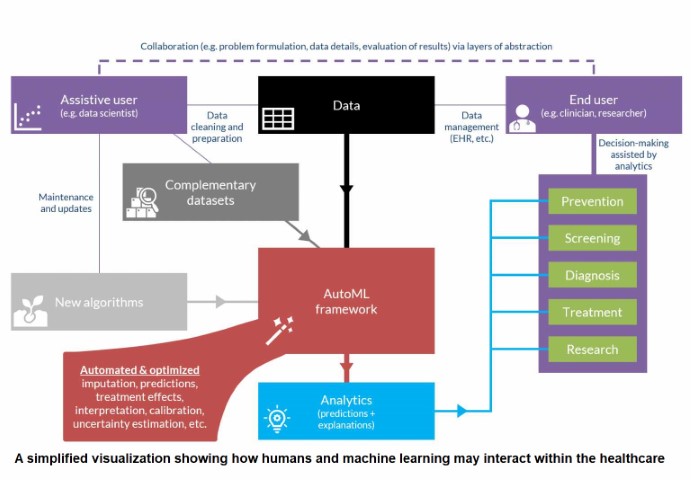
Automated Machine Learning provides methods and processes to make Machine Learning available for non-Machine Learning experts, to improve efficiency of Machine Learning and to accelerate research on Machine Learning.
The high degree of automation in AutoML allows non-experts to make use of machine learning models and techniques without requiring them to become experts in machine learning. AutoML allows for greater access to AI development for those without the theoretical background currently needed for role in data science.
Standard ML approach
In a typical ML application, data science team have a set of input data to be used for training. The raw data may not be in a form that all algorithms can be applied to it. To make the data amenable for machine learning, a team of experts may have to apply appropriate data pre-processing, feature engineering, feature extraction, and feature selection methods. After these steps, team must then perform algorithm selection and hyperparameter optimization to maximize the predictive performance of their model. Each of these steps may be challenging, time and resource consuming, resulting in significant hurdles to using machine learning.
AutoML dramatically simplifies these steps for non-experts. One can think of AutoML - regardless of whether building classifiers or training regressions - as a generalized search concept, with specialized search algorithms for finding the optimal solutions for each component piece of the ML pipeline. In building a system that allows for the automation of just three key pieces of automation - feature engineering, hyperparameter optimization, and neural architecture search - AutoML promises a future where democratized machine learning is a reality.
Advantages of AutoML
There are three main advantages to incorporating AutoML. These are:
- Productivity - automation reduces the manual resources needed to monitor and perform repetitive ML tasks. This frees teams to focus on model refinement and packaging.
- Standardization - automated pipelines help reduce the chance of configuration errors and ensure that training and tests are performed uniformly.
- Democratization - AutoML lowers the barrier to entry for organizations with little to no ML expertise. This increases competitiveness and can increase innovation.